
System Integration, like IT in general, is an ever changing landscape. With new technologies, paradigms and views emerging over time. The last couple of years this rate of change seems to have increased, mainly driven by new technologies. A lot of these new concepts, especially the hyped ones, are seemingly positioned as a silver bullet type solution that alone will solve your integration woes. Unsurprisingly this is rarely (or even never) the case. What I want to do is take a look at the main concepts in the modern integration landscape and put them together to show how they can not only coexist but also complement each other.
The Service Oriented Architecture
The reputation of Service Oriented architectures has declined over the years. However, the concepts of service orientation are still relevant and are driving new service driven paradigms like Microservices. In most cases the examples negatively impacting the reputation of service oriented architectures are a result of poor implementations, not the concepts. Breaking it down, a service oriented architecture is setup like this:

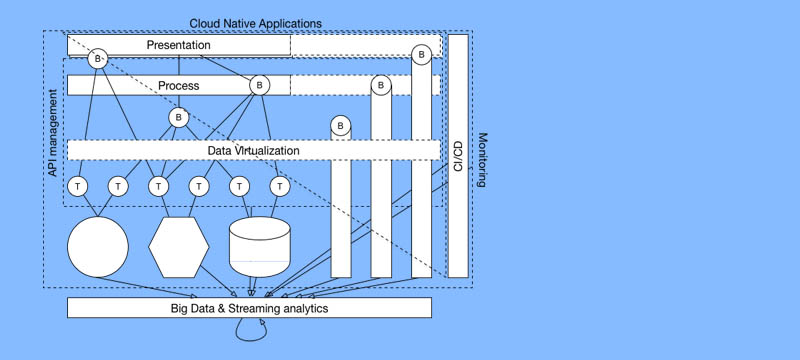
It consists of systems of record that provide technical API’s (T in the diagram) that are tied to their internal system’s operations and data model. These API’s are usually fairly granular CRUD-like operations. On top of these technically oriented API’s an additional business oriented layer is implemented (B in the diagram). This layer aims to provide business relevant functionality that is decoupled from the underlying implementation. Instead of inserting a record into a database you create a new customer. These business oriented API’s are the services that form the foundation for building new processes and applications. The business services are consumed by a process layer that combine the services into processes. These processes can in turn be accessed through various presentation layers like a mobile app or web application, providing the same logic to each. This paradigm is still relevant and needed when working with monolithic applications like purchased (COTS) applications or existing custom or legacy applications. Especially for commodity applications like a HR, CRM or payroll systems it is relevant to be able to access the (business) functionality provided by these systems.
Microservices
The Microservices architecture style is also based on the core principles of service orientation, but it’s main differentiator is how it approaches and implements them. Microservices main driver is autonomy. Not only logically, by providing an autonomous business function, but also in it’s implementation. Microservices strive to be autonomous at runtime too through low coupling and high cohesion. This means that proper microservices can implement a complete stack. This can include a data-source but also process and even presentation logic depending on its relevance to the functional scope of the Microservice. Microservices strive to being autonomous components at every level. By doing so, they are easier to scale, modify and even replace.

The main thing to realize here is that Microservices don’t need to be the only way to go within your architecture. Given their loosely coupled nature they can be mixed with other types of services. From a process (layer) perspective a Microservice is just another service. Why and when to use Microservices is mainly driven by your particular problems and needs. Overall the main drivers behind Microservices are scalability and flexibility. But they also come with the cost of an increased strain on operations. A lot of the benefits currently associated with Microservices apply to service orientation in general. Bounded contexts, low coupling, high cohesion and such should drive any type of service orientation. Implementation decisions like REST vs SOAP are irrelevant for the architecture.
API Management
In a distributed environment it becomes increasingly important to keep tabs on what is going on. In such an environment API management fulfills this role. An API management solution usually consists the API’s, an API Gateway where the API’s are exposed and a developer portal that helps developers discover the API’s.

The API Gateway fulfills a similar role as a flight control tower in an airport. It handles who can access what, how often someone access something and intervenes when a resource might be accessed too much. It also can shape the traffic going to certain API’s. For instance to prevent too many calls or to restrict access after a certain threshold has been reached.
Data Virtualization
In an distributed architecture, especially one based on Microservices, there is an increase in data sources that all can contain important business data. While distributing the data can help with scaling and processing a unified view of that data is often needed. This is where data virtualization comes in. Data Virtualization allows you access heterogeneous data sources as a single source in realtime.

Cloud Native Applications
While the name might be slightly confusing, cloud native aren’t necessarily applications that run in the cloud. Instead the term to the approach of building and running applications that fully exploit the advantages of the cloud computing delivery model. The four main pillars here being DevOps, Continuous Delivery, Microservices and Containers. They can be used to implement presentation and/or process layers, but also be used to implement full stack microservices. These full stack implementation will in turn also expose API’s to allow other applications and services to interact with them.

CI/CD
CI/CD (or Continuous Integration/Continuous Delivery)is a trend in that transcends integration as it’s an important trend in software development in general. It’s an approach to software delivery that focusses on delivering software predictably, reliably and fast. CI/CD enables the delivery of software in minutes instead of days. CI/CD is usually mentioned together with other trends like Agile software development, DevOps and Microservices because the combination allow for the development of small pieces of functionality than can be made available to end-user in very little time.

Monitoring
Monitoring is an important aspect to any type of software but in a distributed environment monitoring becomes increasingly important. Simply because there a lot more components running. Monitoring doesn’t stop with simply collecting and keeping track of the logs of your systems and services it should also provide context to be able to tie individual events together.

Big Data & Streaming analytics
Streaming & big data relate to analysing data in motion and at rest respectively. Big Data boils down to collecting all the data you have from all the data sources you have. These aren’t only the systems and Microservices but also other sources like API management, monitoring tools and events happening in the environment. All of this data combined enables running analysis (aided by machine learning) on what is happening within your organization and provide information across systems and services. Streaming analytics act on the data as it flows based (amongst other possibilities) on the output from Big Data and in turn analysis from the streaming data feeds back into the Big Data analysis.





